- Published on
Running Spark in local machine
Overview
Sometimes, you need to run in a fast way on Spark. Maybe you want to conduct some quick tests, so let's see it.
Requirements
You must have the following installed on your system:
- Docker
- Web Browser
Running the Docker Notebook
Just run the following command in your terminal to run on port 8888:
docker run -it --rm -p 8888:8888 jupyter/pyspark-notebook
Docker will download all related repositories.
After running the command, you will see some URLs in the terminal. Test one of them to open your Jupyter Notebook in your browser.

In the Jupyter Notebook
Well now in you notebook just open a new one, and install findspark:
!pip install findspark
And go ahead with the Spark journey!
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer')
.config('spark.sql.hive.convertMetastoreParquet', 'false').config("spark.sql.shuffle.partitions", "2001").config("spark.driver.maxResultSize", "4g").config("spark.driver.memory","10g").getOrCreate()
)
print(spark)
This will give you a response like:
<pyspark.sql.session.SparkSession object at 0x7fbe3f6357d0>
Reading data
So, this container allows you to upload your data to read them. Just load the files or folders, then left-click and copy the path to read them in your code, like this:
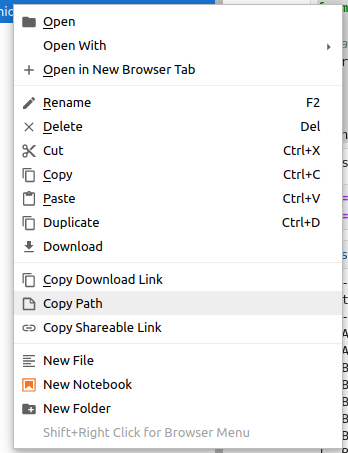
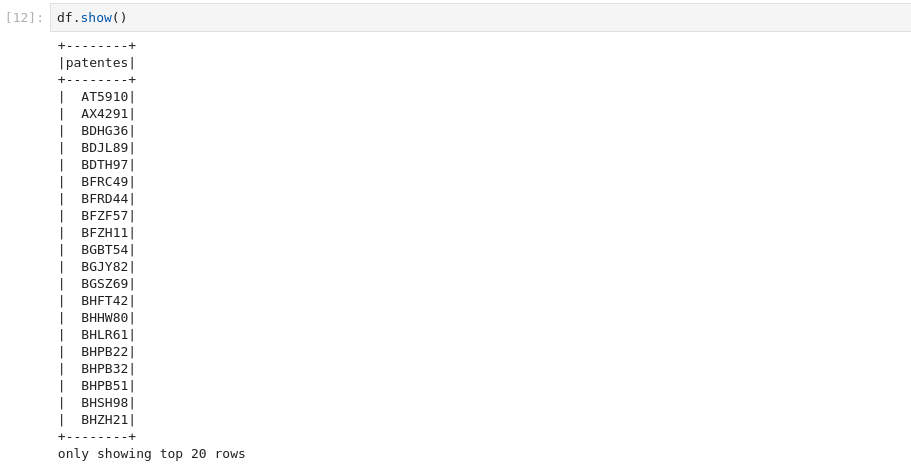
df = spark.read.option("delimiter", ",").option("header",True).csv(f"loaded_file.csv")
df.show()
Stop the container at the end
At the end, you can stop the Docker container or remove the image if necessary.
In a terminal, list the containers that were running by using the following command, and then copy the ID:
docker ps
To stop the container with the ID, replace <ID> with the actual ID of your container.
docker stop <ID>