- Published on
Review Lambda latency
Overview
This post it's based in the documentation of AWS related and my experience developing some architectures.
Understanding Lambda Latency
In the world of AWS, Lambda is a powerful service that operates within a runtime environment, commonly known as an execution context. Visualize this context as a small container allocated with specific resources, which diligently executes your Lambda code.
Lambda lifecicle
Gain insight into the complete sequence of events and states that a Lambda function undergoes, encompassing creation, execution, and eventual termination.

The Cold Start Phenomenon
When a Lambda function is initially invoked, such as when it receives an S3 event, an execution context must be created and configured. This process requires time and entails several crucial steps. First, the environment itself is created, involving the allocation of physical hardware resources. Following that, any necessary runtimes, like Python 3.10 or a Docker image from ECR, are downloaded and installed within the environment. Lastly, the deployment package associated with the lambda function is retrieved and installed, adding further time to the process.
A cold start involves the full creation and configuration of an execution context, taking approximately ~100ms, including the function code download.
The Warm Start Phenomenon
When the same Lambda function is invoked again without a significant time gap, Lambda can utilize the existing execution context. This means there is no need to set up the environment or download the deployment package, as everything is already contained within the context. In a warm start scenario, the context simply receives the event and promptly begins processing. As a result, the code can start running within milliseconds, typically around ~1-2 ms, without a lengthy build process.
However, if a considerable amount of time passes between invocations, the execution context may be deleted, leading to another cold start. It's important to note that each execution context can only handle one function invocation at a time.
To optimize this process, you can leverage a feature called Provisioned Concurrency. By informing AWS in advance and adjusting the concurrency settings, you can have execution contexts provisioned beforehand for Lambda invocations. This is particularly useful when anticipating periods of higher load or preparing for a new production release of a serverless application, as it allows you to pre-create the necessary execution environments.
There are additional measures you can take to improve performance. For example, using the /tmp space within the execution context to pre-download necessary data in the initial iteration. Subsequent event executions can then verify the presence of data in the /tmp folder of the Lambda function.
If a cold start is unavoidable in your process, there are two potential approaches. One option is to delete all data upon completion and oversize the ephemeral storage. Alternatively, you can introduce a time delay between executions and make a note that each execution could potentially run in parallel.
Lambda limitations
Remember in Lambda:
1 vCPUis equivalent to1769 MBof RAM and is proportional.- Memory allocation ranges from 128 [MB] to
10240 [MB]. - The maximum runtime for a Lambda function is
15 [min]or 600 [sec].
Study case
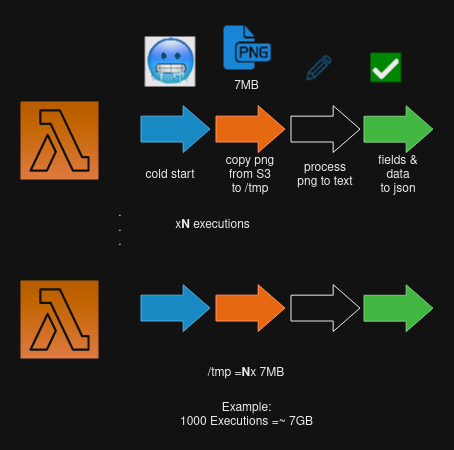
In a specific instance, a customer required a high-intensity utilization of a Lambda function to convert textual content from an image into structured "JSON" text, and subsequently store it in a database. Due to confidentiality concerns, I am unable to provide further details about the use case, but I can focus on the architecture and the Lambda latency. Because the concurrency was intensive and the ephemeral storage was compromised by the N excecutions in parallel.
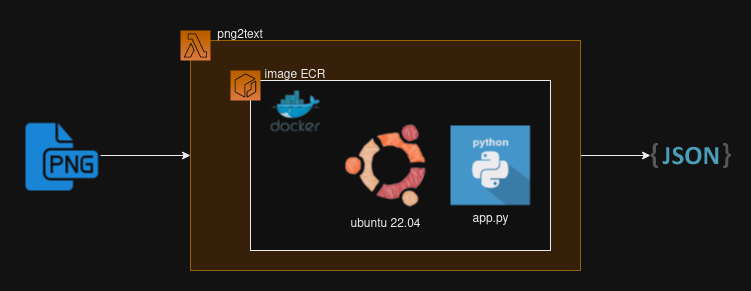
The critical process in the code was encountered when I copied the PNG file from S3 to the /tmp directory using Python:
s3_client.download_file(bucket, object_key, download_path)
And for this intensive copy and paste was necesary delete the file until the lambda termination:
os.remove(download_path)
So the principal problem in this case is the ephemeral storage, and the concurrency.
The solution
- Limit the concurrency, in this case was update to 700 at time.
- Reserve a ephemeral storage , here was 6 GB.
- delete the files until the ends.
Key recommendations
-
If you create something outsite of the Lambda function handler like DB conection this will be enable for any future function invocations in the same context.
-
If you require a cold start in parallel, it's essential to be cautious about the ephemeral storage, as the Lambda function could fail due to this factor.